音视频分割任务旨在根据音频信息精准定位画面中发声物体,并在像素级别完成分割,例如识别并分割出视频中唱歌的人。然而,声音的语义往往存在模糊性——猫叫声与婴儿哭声极其相似,当两者同时出现在画面中时,现有技术常难以区分。此外,如何将音频信号与像素级信息在时空维度上一一对应,也是一项艰巨挑战。
为解决上述难题,浙江大学人工智能团队提出了一种全新的音视频分割框架CATR(基于组合依赖与音频查询的Transformer),在三个主流数据集上均达到当时的最优性能,成果被多媒体国际会议ACM MM 2023录用并授予唯一最佳论文奖(从3072篇投稿中脱颖而出,是该奖项首篇以浙大为第一单位的获奖论文)。
CATR的主要贡献有以下几点:1.设计了解耦的音视频编码器。在编码阶段,CATR提出的解耦的音视频编码器将音频特征和视频特征分别从时间维度和空间维度进行多种组合化的交互,通过堆叠模块,可以在节约内存的基础上对音视频进行更细粒度的交互。2. 提出了组模块门控机制。CATR设计的门控机制可以充分利用每个编码器块抽取的视频特征,平衡多个编码器块中交互特征的贡献。3. 引入了基于多查询头的音频约束。CATR设计了一组可学习的查询头,并使用动态解码核为每个查询头生成相应的分割掩码,最后从多个查询头中匹配出最佳的分割结果。
CATR在三个主流的数据集上进行了充分的定性和定量的实验,并达到了最佳性能。其中,模型在多源音频的数据集上提升最为显著(在Jaccard index指标上提升了4.9个点,在F-score指标上提升了7.5个点)。在实际应用中,CATR表现出了优异的性能,他能更敏锐地识别发声物体的转换,同时在复杂背景下实现更准确的像素级预测。
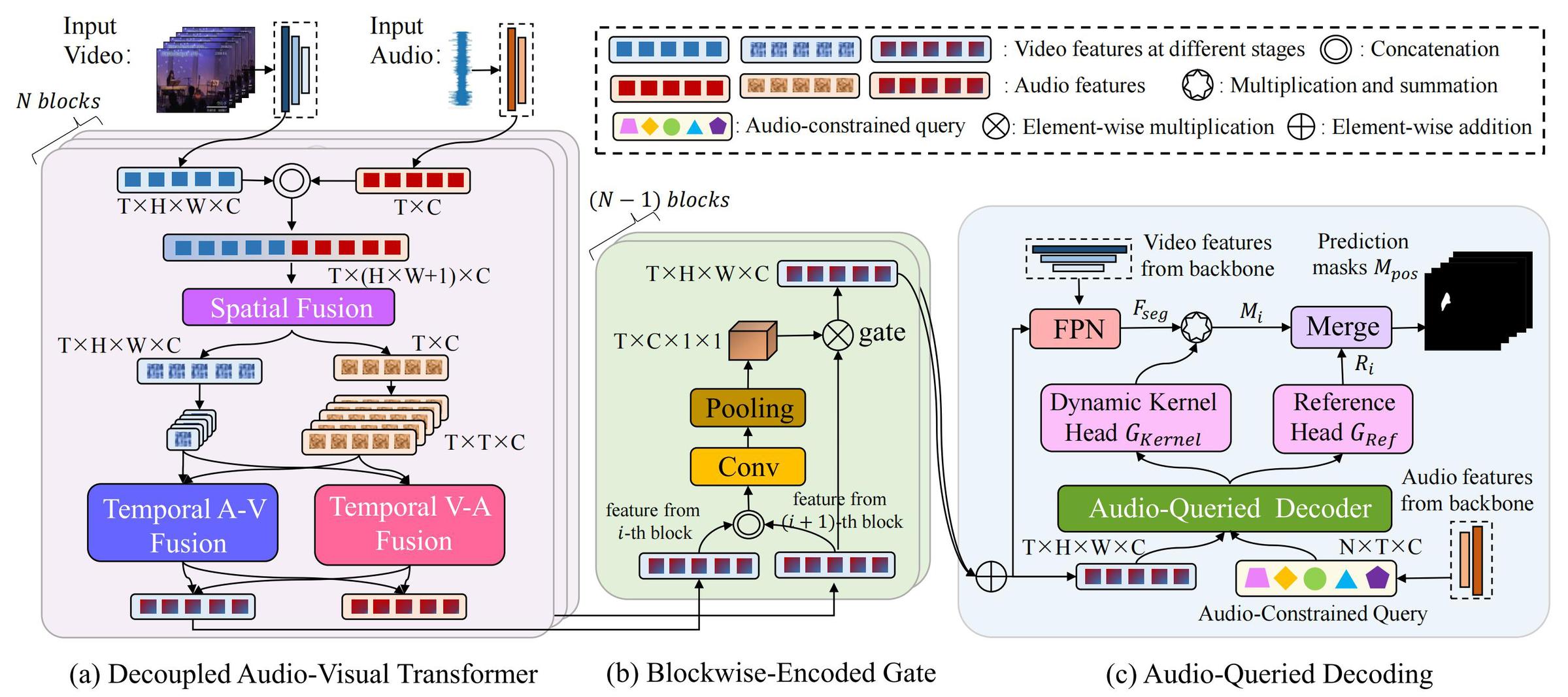
CATR框架:(a) 解耦的音视频交互编码器 (b) 组模块门控机制 (c) 基于音频查询解码器
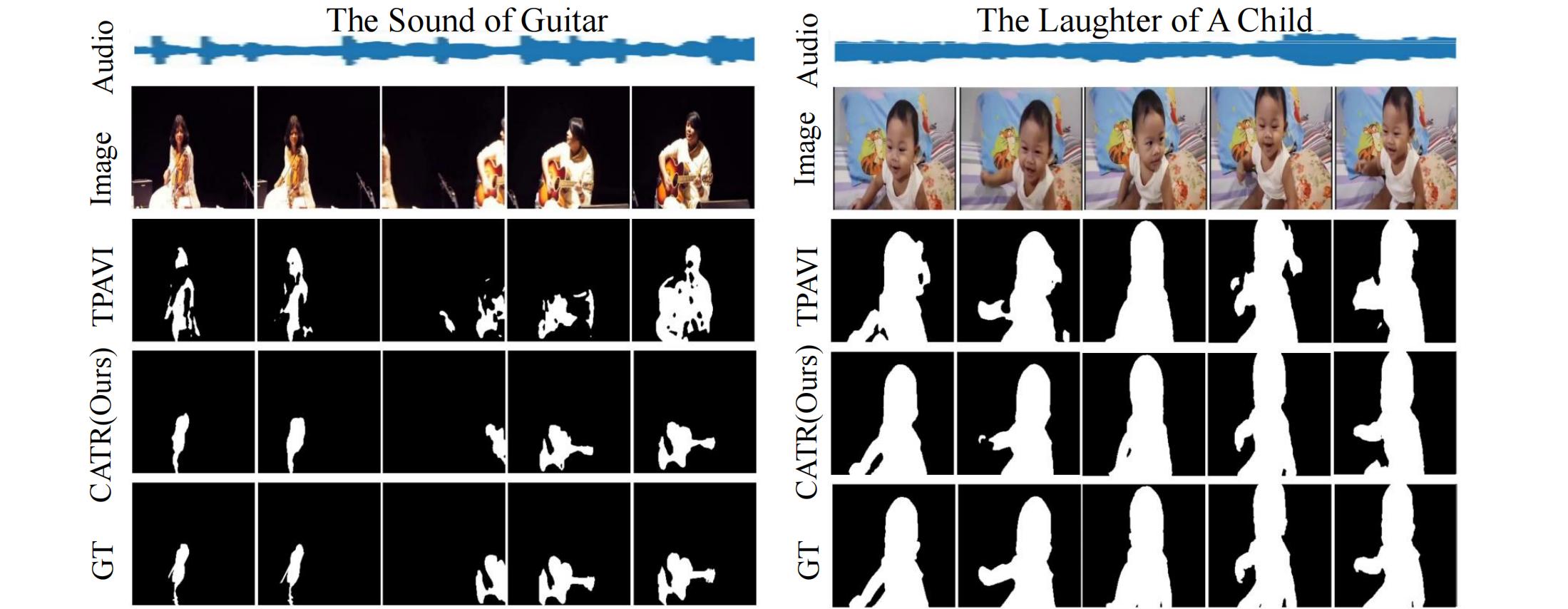
分割结果对比:CATR模型在理解音频信息转换和像素级分割上都展现了更为优越的性能。
论文原文链接:
Kexin Li, Zongxin Yang, Lei Chen, Yi Yang, and Jun Xiao. 2023. CATR: Combinatorial-Dependence Audio-Queried Transformer for Audio-Visual Video Segmentation. In Proceedings of the 31st ACM International Conference on Multimedia (MM '23). Association for Computing Machinery, New York, NY, USA, 1485–1494.