导 读
化学数据“孤岛”难题如何破解?实验室在《自然·通讯》发文提出CKIF框架,这项研究从人脑协同机制获得灵感,让AI像科学家一样“思考”,不共享数据也能实现知识融合。想知道AI如何像人脑一样“偷师学艺”?下面让我们一探究竟!
浙江大学脑机智能全国重点实验室王文冠研究员、杨易教授课题组近日在《自然·通讯》(Nature Communications)上发表题为“Chemical knowledge-informed framework for privacy-aware retrosynthesis learning”的研究论文。该研究提出一种面向化学反应逆合成的隐私保护机器学习框架CKIF(Chemical Knowledge-Informed Framework),致力于解决化学反应逆合成研究中长期存在的“数据孤岛”问题,即各机构因数据敏感而难以共享、协同利用反应数据的问题。
CKIF首次实现了跨机构的分布式协同逆合成模型训练。各参与方无需共享或传输任何原始化学反应数据,规避了因数据泄露带来的安全风险。该框架创通过引入基于化学专业知识的模型参数聚合机制,在保障数据安全与隐私的同时,实现了化学专业知识的高效注入和多方数据的有效融合,为逆合成模型的协同训练开辟了全新范式,同时也为药物研发和材料设计提供了更智能、更安全的AI解决方案,展现了人工智能在化学合成领域的应用价值。

研究背景与问题
逆合成(Retrosynthesis)是有机化学的核心方法之一:从目标分子出发,逆向推导出合理且高效的合成路径,在新药研发、新材料创制以及化学工艺优化中发挥着关键作用。近年来,随着人工智能,尤其是机器学习模型的广泛应用,逆合成分析的效率显著提升,预测成功率大幅提高。
然而,当前主流的机器学习逆合成方法,无论是基于模板、无模板还是半模板的,均依赖于同一种训练模式:将来自多方的化学反应数据汇聚至单一中心服务器,进行集中式模型训练。这一模式与当前现状存在很大差距:化学反应数据是高成本积累的宝贵资源,也涉及企业的核心技术机密、知识产权与竞争优势。出于商业保密与数据安全的考虑,各大机构对共享原始数据普遍持高度审慎态度,导致了“数据孤岛”现象:大量有价值的数据被封锁在各自机构内部,难以共享。
“数据孤岛”现象已构成制约该领域发展的关键瓶颈,使数据驱动的人工智能方法无法充分发挥潜力。因此,如何在无需共享原始数据的条件下,可实现跨机构的安全协同,已成为一个亟待突破的重要挑战。针对这一挑战,本研究提出一种仅通过交换模型参数即可实现多方协同优化的隐私保护逆合成框架,为破解数据壁垒、推动领域协同发展提供了原创性解决方案。
化学知识引导的隐私保护逆合成学习框架
本研究提出并验证了一种面向化学逆合成的隐私保护学习框架CKIF(Chemical Knowledge-Informed Framework)。该框架突破了传统机器学习在化学领域的两种典型训练模式:其一是各机构基于自有数据独立建模的“本地训练”模式,其二是将多方数据集中于单一服务器进行训练的“集中式训练”模式。CKIF构建了一种安全高效的分布式协同学习机制,整个过程通过多轮迭代推进,每轮迭代包含以下两个关键阶段:
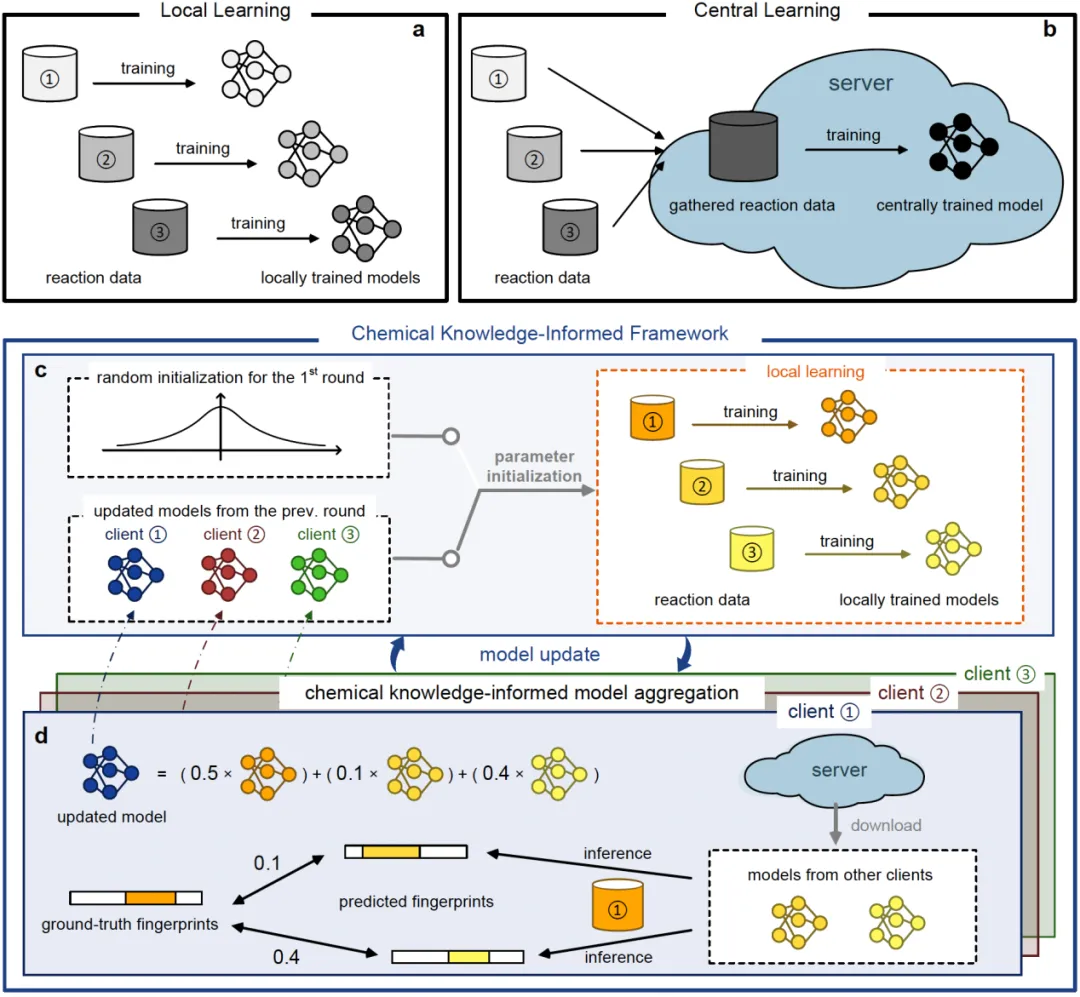
第一阶段:本地模型训练
所有参与机构均使用本地存储的私有数据,独立训练各自的逆合成预测模型。在整个过程中,原始反应数据始终保留在本地,不对外传输。训练完成后,各机构仅将模型参数上传至中央服务器,原始数据不作任何共享。
第二阶段:化学知识引导的个性化模型聚合
中央服务器在收齐各机构上传的模型参数后,并不采用传统联邦学习中常见的全局平均策略(如FedAvg),即简单加权生成一个统一的“全局模型”。这种做法在各机构数据分布差异显著(例如研究方向、反应类型不同)时,往往导致模型泛化能力下降。为此,CKIF引入了一种面向个体的个性化聚合机制。
具体而言,CKIF为每个参与机构定制专属的优化模型。为此,框架引入化学知识引导的权重分配策略(Chemical Knowledge-Informed Weighting, CKIW)。以机构A为例:系统会使用其本地的验证集数据,分别评估其他机构(如B、C、D)模型在其任务上的表现。评估的核心依据是反应产物的化学相似性——即通过分子指纹计算其他机构模型预测的反应物与机构A真实反应物之间的结构相似度。若机构B的模型在机构A的数据上表现出较高的预测一致性,则表明其模型所蕴含的化学知识对A具有较高参考价值。在模型聚合时,CKIF据此为机构B的参数分配更高的融合权重。通过这种方式,每个机构最终获得一个融合了“化学知识”且高度适配自身数据特征的新模型。
每轮迭代结束后,各机构均可获得一个融合多方优势且适配自身数据分布的新模型。该模型将作为下一轮本地训练的初始模型,进入下一周期。通过多轮迭代,所有参与方的模型得以在保障数据隐私的前提下,持续优化、协同演进。
主要发现
该研究通过系列实验全面检验了CKIF的有效性、可扩展性和鲁棒性:
1.在基础协同学习场景中表现出色,显著优于各类基准方法。
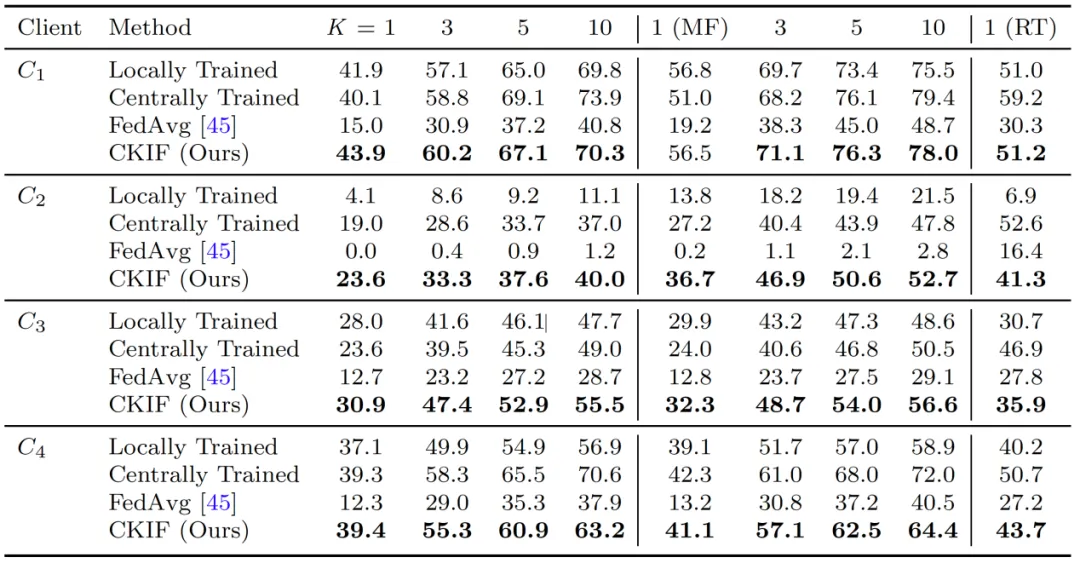
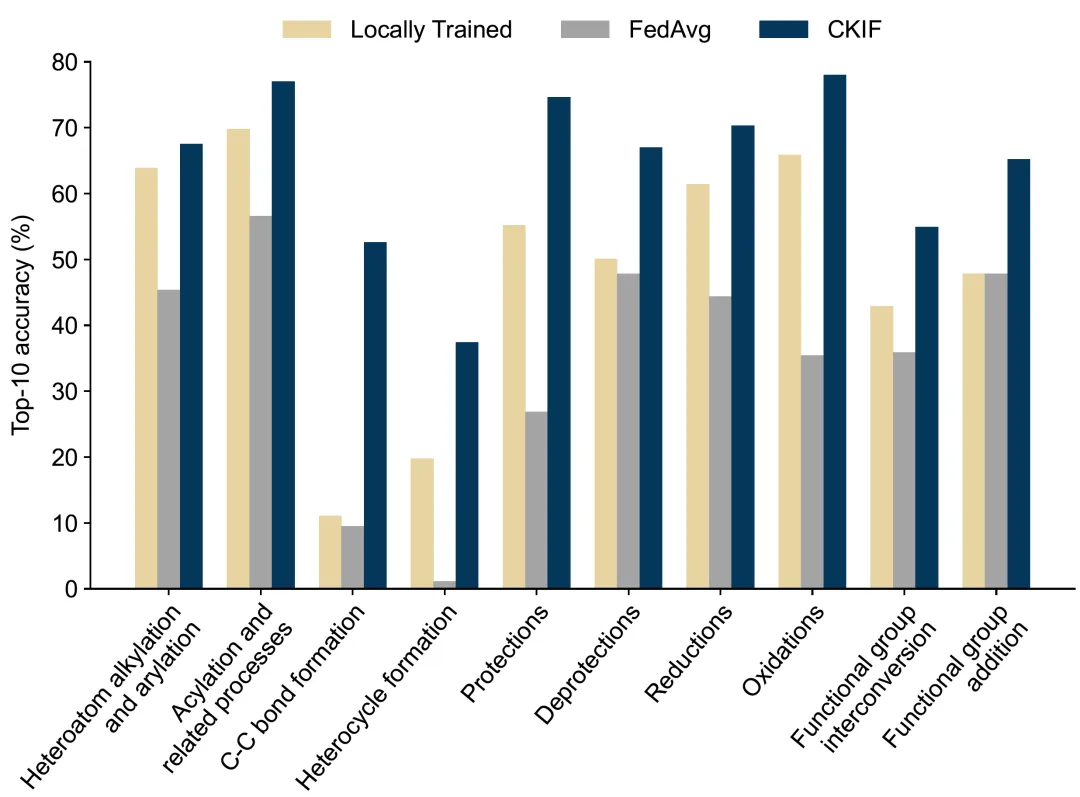
在基于USPTO-50K数据集的四客户端实验设置下,CKIF框架在多项指标上显著优于各参与方独立训练的“本地化学习”模型(Locally Trained)。同时,其性能全面超越主流联邦学习方法FedAvg,在部分任务上甚至达到或超过依赖数据集中化的“中心化学习”模型(Centrally Trained),展现出强大的协同建模能力。
表1 CKIF与各基准方法在USPTO-50K数据集上的Top-K准确率对比
2.具备良好的客户端可扩展性,模型性能随参与方增加而持续提升。
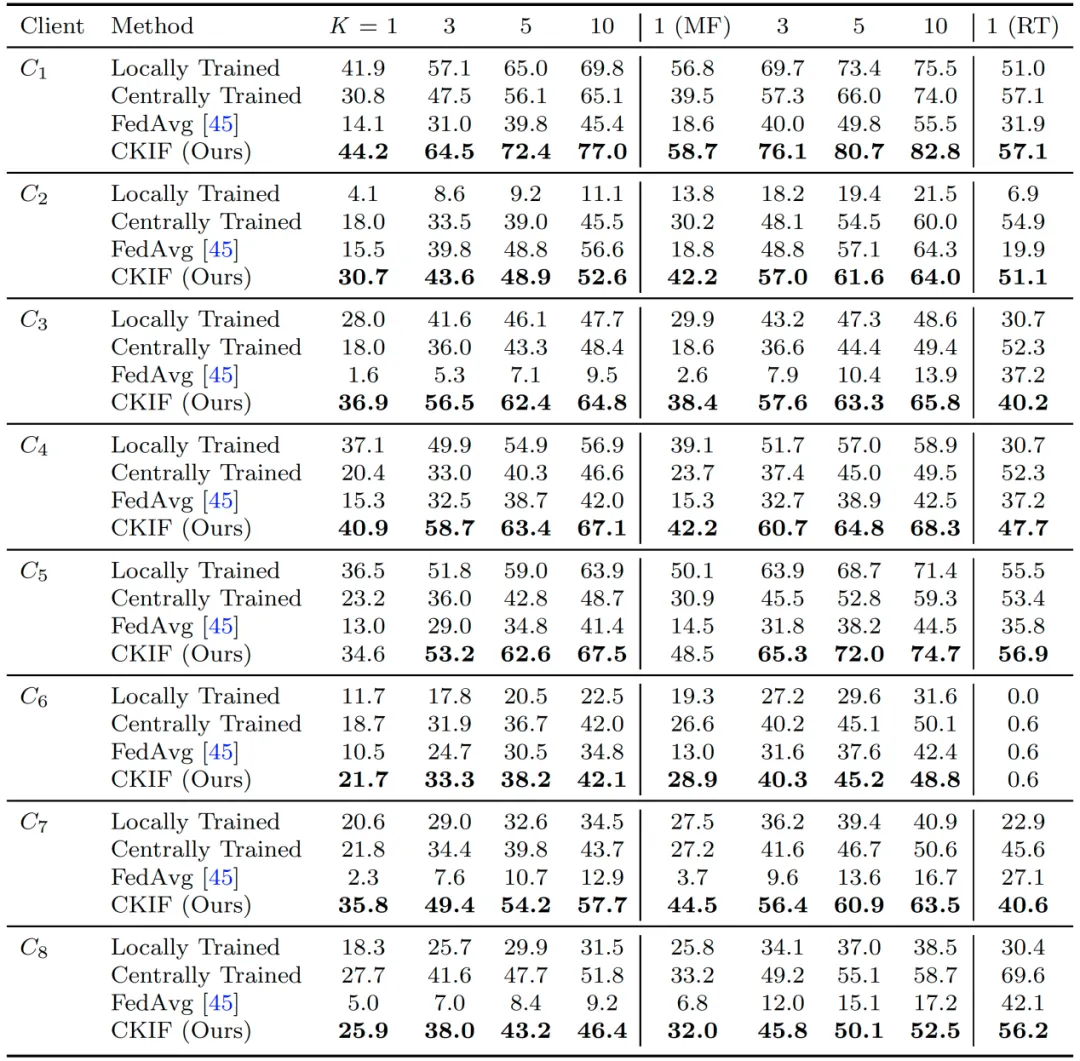
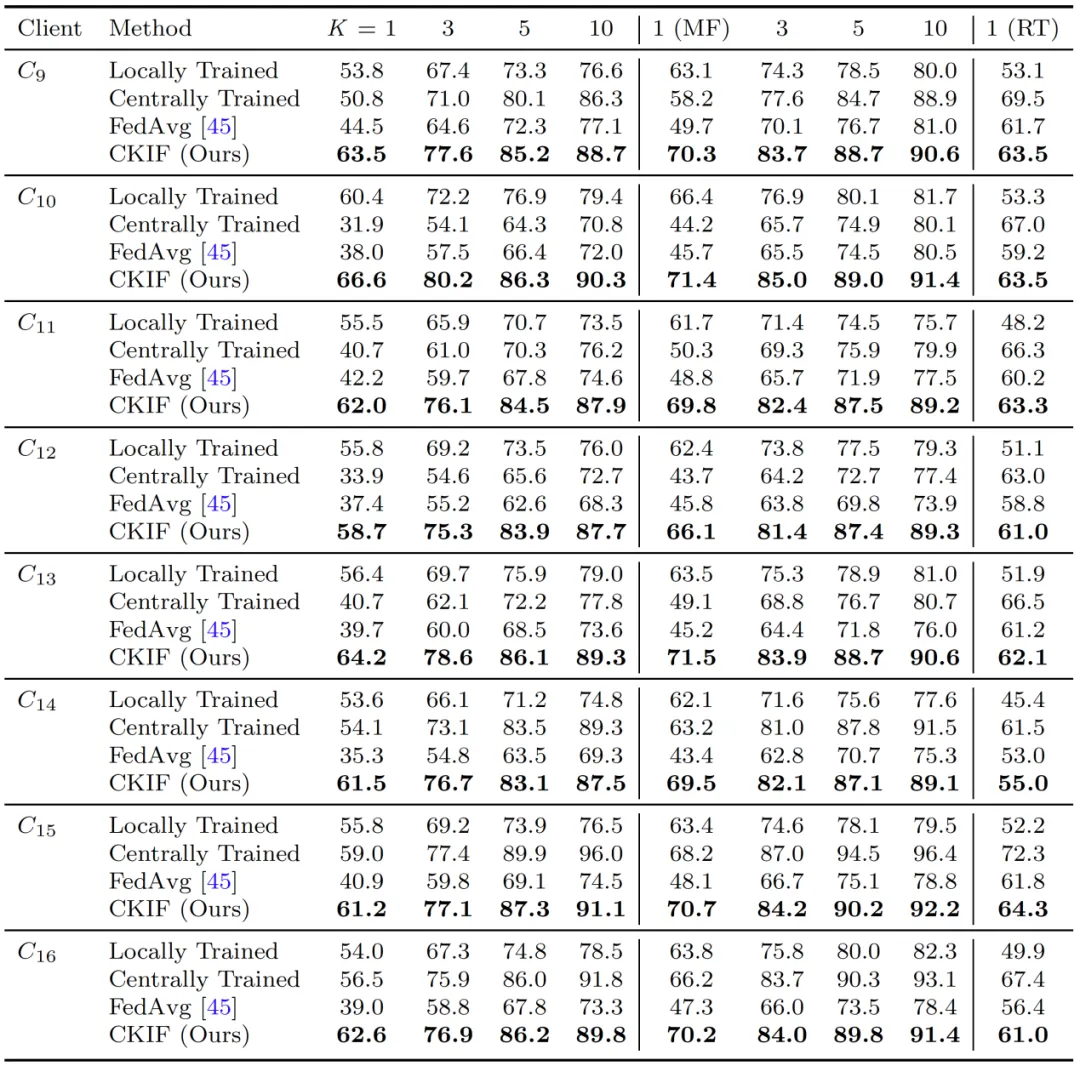
在基于USPTO-50K与USPTO-MIT数据集的实验中,当参与客户端数量从四个增至八个时,所有参与方的模型性能均进一步提高。结果表明,CKIF能够有效整合更多参与方的数据,且模型增益随协作规模扩大而增强,展现出良好的可扩展性。
表2 CKIF与各基准方法在USPTO-50K和USPTO-MIT数据集上的Top-K准确率对比
3.在数据充足场景下仍具增益能力,体现框架的广泛适用性。
为评估CKIF在数据丰富环境中的有效性,研究在数据规模更大的USPTO 1k TPL数据集上开展了实验。结果表明,即使各参与方本地数据充足、“本地化学习”模型已展现优异性能,CKIF仍能带来显著提升。该结果说明,CKIF不仅适用于数据受限场景,亦可在高数据量条件下作为通用增强机制发挥作用。
表3 CKIF与各基准方法在USPTO 1k TPL数据集上的Top-K准确率对比
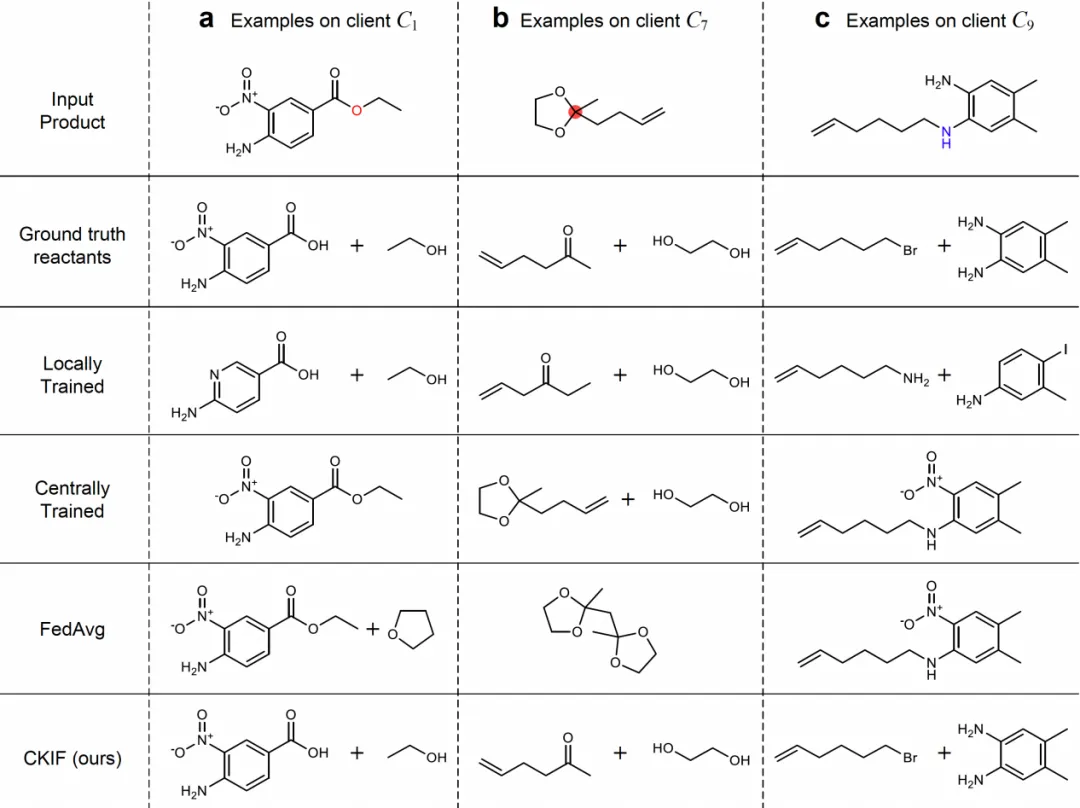
4.对多种化学反应类型均具优势,且预测结果体现更强的化学合理性。
研究对USPTO-50K数据集的十类主要化学反应进行了系统评估,CKIF在所有类别上均一致且显著优于基准模型。这一优势不仅体现在整体准确率上,更反映在具体反应路径的预测质量中。例如,在复杂成环反应的案例分析中,其他基线方法因难以捕捉关键结构特征而产生错误预测,而CKIF能够准确推导出符合化学原理的反应物,表明其对反应机理具有更强的建模能力。
5.敏感性分析与机制验证。
为验证CKIF的核心机制及其在不同配置下的稳定性,研究系统评估了化学知识引导权重策略(CKIW)的有效性及模型对关键超参数的敏感性。实验表明,采用CKIW的模型优于基于数据量加权的传统聚合方式。同时,模型准确率随通信轮数增加而持续提升,展现出良好的收敛性;在2至4个客户端的设置下,性能随参与方数量增加而显著上升,表明框架具备良好的可扩展性。
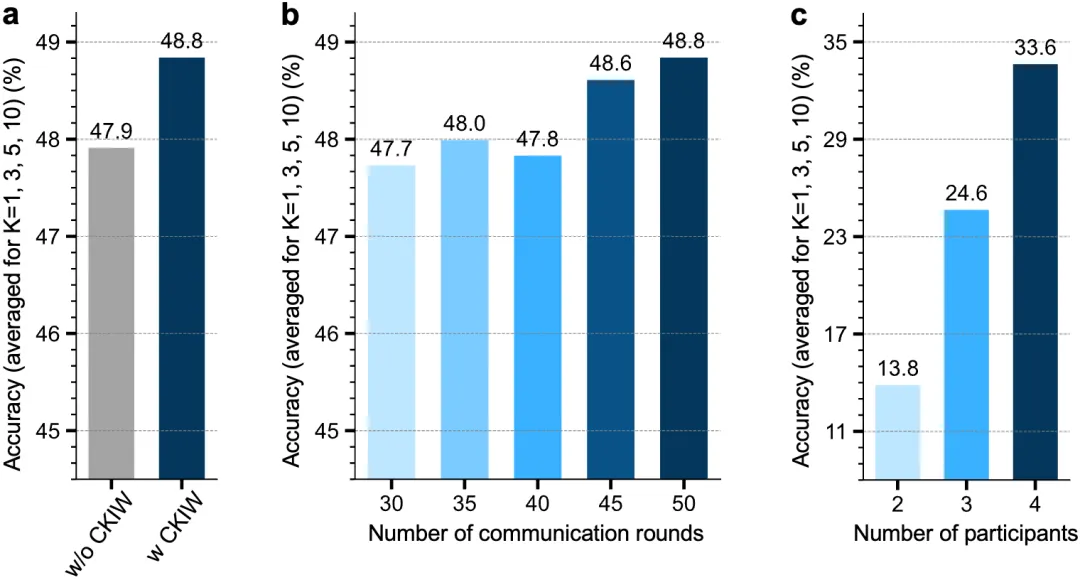
图4 消融实验分析
6.具备良好鲁棒性,能有效缓解数据污染的影响。
在模拟真实场景中数据存在噪声的实验中,即使客户端数据包含5%至20%的错误反应记录,CKIF仍能保持稳定性能,显著优于在相同污染数据下训练的“本地化学习”模型。这一优势源于CKIW策略能够动态评估各参与方模型的可靠性,并降低来自低质量数据源的模型权重,从而有效抑制噪声传播,提升整体系统的稳健性。
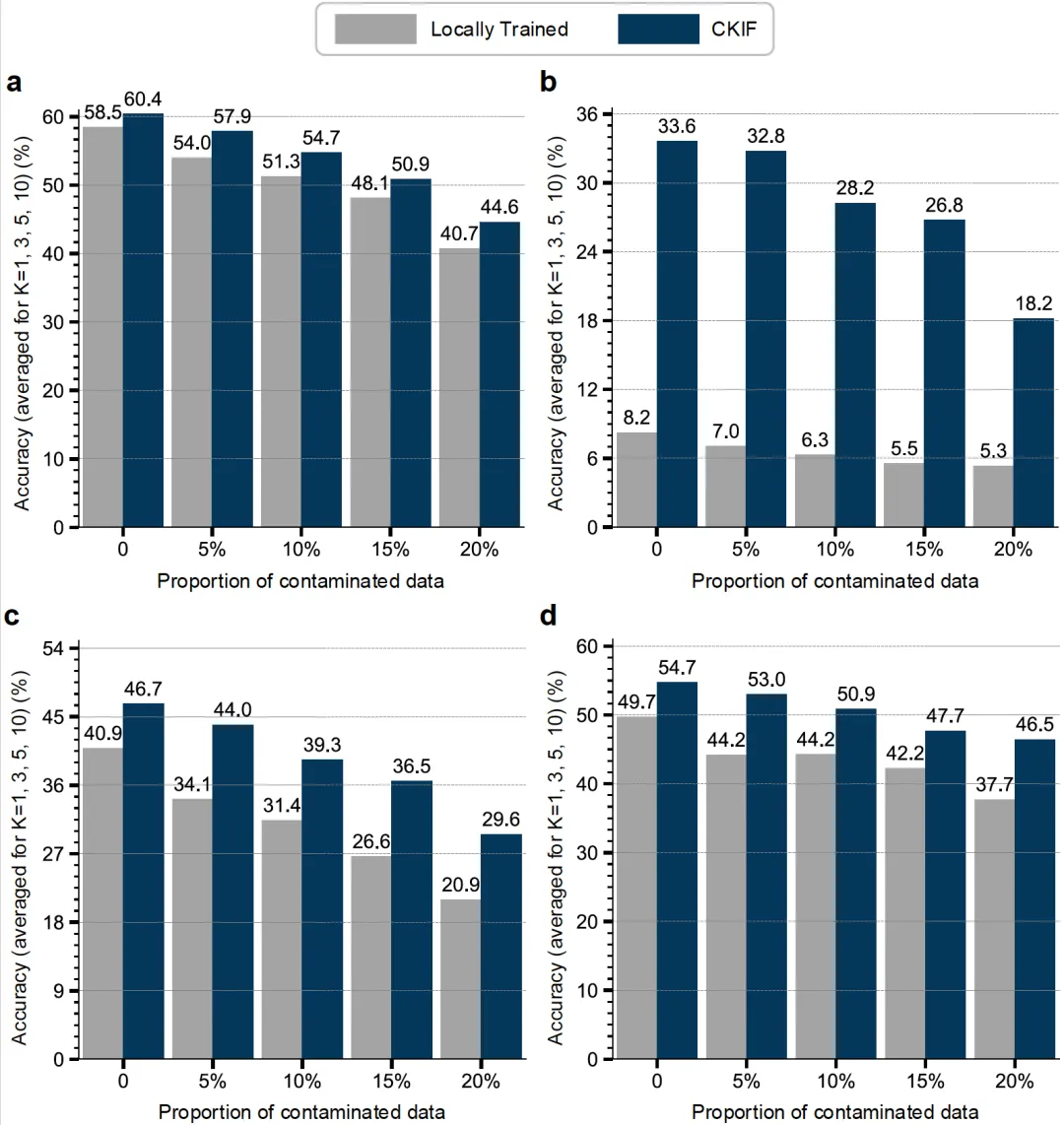
图5 CKIF框架在数据污染下的鲁棒性分析
研究意义与应用
该项研究提出了一种全新的技术路径,为破解敏感科研数据难以共享的困境提供了可行的解决方案。CKIF框架能够帮助打破机构间的数据壁垒,使多方在不共享原始数据的前提下实现数据协同,提升逆合成模型预测的准确性与泛化能力。这一能力将进一步加速新反应路径的发现与优化,为新药创制、功能材料设计以及高效催化体系开发等关键领域提供有力支撑。CKIF不仅为逆合成研究构建了首个基于化学知识引导的隐私保护协同学习范式,也为其他科学领域中高价值、高敏感数据的分布式建模提供了可借鉴的方法论框架。尽管CKIF展现出良好的应用前景,研究团队也指出了若干值得深入探索的方向,例如如何应对参与方数据质量不均的问题,以及如何进一步优化知识评估机制,以适配不同机构的研究重点与数据特征。此外,尽管CKIF未专门设计用于抵御恶意攻击,但其模块化架构可自然兼容差分隐私、模型加密等现有隐私增强技术,具备良好的安全扩展潜力。
本项工作由浙江大学脑机智能全国重点实验室、计算机学院和中国人民大学高瓴人工智能学院共同完成。浙江大学陈桂锟博士生为本文第一作者,浙江大学脑机智能全国重点实验室、计算机学院王文冠研究员为本文通讯作者。浙江大学杨易教授课题组和中国人民大学刘勇教授课题组也为本文做出了重要贡献。本研究主要受科技部科技创新2030—“新一代人工智能” 重大项目、国家自然科学基金、中央高校基本科研业务费专项资金、浙江省自然科学基金重大项目等资助。
原文链接:
https://www.nature.com/articles/s41467-025-63036-7